以下の実習用基本ソースコードをコピーして利用する.*赤文字部分を編集する.
;***********************************************************
; step04 for PIC16F84A
; step04.asm, H. OSADA, Nov. 2021
;***********************************************************
;
;=================================================
; definitions
;=================================================
;- hardware -----------------------------------
LIST P=PIC16F84A
#INCLUDE "P16F84A.INC"
;
__CONFIG _HS_OSC & _WDT_OFF & _PWRTE_ON
& _CP_OFF
;
;- constant label -----------------------------
;**name EQU **value
;
;- file register ------------------------------
CBLOCK 0CH
;**name
ENDC
;
;=================================================
; run start
;=================================================
;- reset start --------------------------------
ORG 0
GOTO INIT
;
;- interrupt start ----------------------------
ORG 4
GOTO ISR
;
;- initialize ---------------------------------
INIT
;**module settings
;
;=================================================
; main routine
;=================================================
MAIN
;** procedure
;
;=================================================
; interrupt service routine
;=================================================
ISR
;** procedure
;
;=================================================
; subroutine
;=================================================
;** procedure
;
;***********************************************************
END |
| ◆4.3.1 バイト定数と変数の設定 |
| ▼定数の定義 |
プログラムで使用する定数は EQU 命令によりラベルを定義できる.通常はプログラムの先頭部分に定義する.
なお,定数範囲は 000H〜0FFH までである.
以下に,MAX と MIN という定数(それぞれ 240 と 0 )を定義した例を示す.
MAX EQU 0F0H
MIN EQU 000H |
|
|
|
| ▼変数の定義 |
PIC16F84A では,データメモリ中の 0CH〜4FH 番地までの 68 個のレジスタが変数として利用できる.
各変数用レジスタは EQU 命令および CBLOCK〜ENDC 命令によりラベルを定義することができる.通常はプログラムの先頭部分(定数の定義後)に定義する.
定数の定義と区別するため,CBLOCK〜ENDC 命令で記述されることが多いが,データメモリの範囲を超えないように注意すること.
以下に,data1 と data2 という変数(それぞれ 0CH と 0DH 番地)を定義した例を示す.
・EQU を利用する場合
data1 EQU 0CH
data2 EQU 0DH |
・CBLOCK〜ENDC を利用する場合
CBLOCK OCH
data1
data2
ENDC |
|
|
|
| ▼変数の初期化 |
変数を初期化(初期値の設定)するには,通常 MOVLW 命令にとMOVWF 命令を利用する.
すなわち,MOVLW 命令でリテラルデータを Wreg に格納し,MOVWF 命令で指定されたレジスタに転送する.リテラルデータは数値以外にも定数ラベルによっても指定できる.
また,0 に初期化する場合に限り,CLRF 命令も利用できる.
以下に,変数 data1 と data2 に対して,それぞれ 0 と 240 (F0H もしくは定数
MAX)という値を設定した例を示す.
・定数ラベルを利用しない場合
MOVLW 000H
MOVWF data1
;
MOVLW 0F0H
MOVWF data2 |
・定数ラベルを利用する場合
MOVLW MIN
MOVWF data1
;
MOVLW MAX
MOVWF data2 |
・CLRF 命令を利用する場合
CLRF data1
;
MOVLW MAX
MOVWF data2 |
・プログラムメモリ内に定義した定数を利用する場合
サブルーチンコールを利用することで,任意の場所の定数を読み込むことができる.
MOVLW 0
;set adr 0
CALL INIT_DATA
MOVWF data1
MOVLW 1
;set adr 1
CALL INIT_DATA
MOVWF data2
;
INIT_DATA
ADDWF PCL,F
RETLW D'0' ;adr 0
RETLW D'240'
;adr 1 |
|
|
|
|
|
| ◆4.3.2 ビット変数(フラグ)の設定 |
処理が複雑なプログラムになるに従い,多くの変数を利用して処理を制御する必要が出てくる.それらの変数で,0
か 1 という 2 つの値のみを持つ変数をビット変数もしくはフラグと呼ぶ.
フラグは,プログラム実行中に,任意の処理が実行されたかどうか(条件を満たしたかどうか:“オン/オフ”)を記憶させ,後の処理で参照するために用いられる.
| ▼フラグの定義 |
0 か 1 を格納できればよいため,任意の変数の任意ビットを利用できる.
例えば,変数 mode を定義し,その第 0 ビットおよび第 1 ビットをそれぞれフラグ(フラグ名:F_START,F_RESET)として利用する場合は以下のように定数と変数をセットで定義する.(フラグ名の記述に制約はないが,他の定数や変数と明示的に区別するために,“F_”等を付けるとわかりやすい).
・フラグビット定義
F_START EQU 00H
F_RESET EQU 01H |
・フラグビットを含む変数を定義
|
|
|
| ▼フラグの利用法 |
フラグに 0 か 1 を設定するには,通常BSF 命令にとBCF 命令を利用する.
・F_START に 1 を設定
・F_RESETに 0 を設定
設定されたフラグの状態を参照して処理を制御するには,分岐処理(レジスタの任意ビットの状態による分岐)を利用する.
・BTFSS を利用した場合
BTFSS mode,F_START ;if
F_START==1 goto START_on
GOTO START_off
START_on
;F_START=1
GOTO PROC_END
START_off
;F_START=0
PROC_END |
|
|
|
|
|
| ◆4.3.3 分岐処理 |
プログラミングとは,すなわちそのほとんどがプログラムの流れ(分岐処理)を設計することである.したがって,分岐処理の方法をマスターすればプログラミングが容易になる.
分岐処理は,以下に示すタイプに分類できる.算術演算結果による分岐とレジスタの任意ビットの状態による分岐がある.
また,算術演算結果による分岐には,大小比較による分岐と零かどうかによる分岐(カウントダウン結果による分岐を含む)に分けて考えることができる.
| ▼大小比較による分岐 |
減算等の結果を利用して分岐する.
演算結果はSTASTUS レジスタの C ビットで判断する.
例として,変数 data1 と data2 の大きい方を変数 result に格納するコードを考える. |
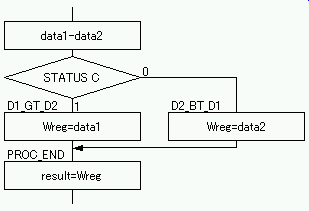 data1-data2 を実行したとき: data1-data2 を実行したとき:
・data1≧data2 なら C=1.
・data1<data2 なら C=0.
C による分岐は BTFSC 命令もしくは BTFSS 命令で行う.両命令は論理が反転しているだけで動作は同様である.
なお,C ビットが 1 の時は演算結果がおおむね正であると言うことができるが,例えば
F0H-20Hの 演算結果は D0(2 の補数形式の場合は負)であるが C=1 となるため,注意が必要である.
算術加算した場合は,オーバーフロー(加算結果が FFH(255)以上)の場合に
C=1 となる.
|
・BTFSS を利用した場合
MOVF data2,W
SUBWF data1,W
BTFSS STATUS,C
GOTO D2_GT_D1
D1_GT_D2
MOVF data1,W
GOTO PROC_END
D2_GT_D1
MOVF data2,W
PROC_END
MOVWF result |
・BTFSC を利用した場合
MOVF data2,W
SUBWF data1,W
BTFSC STATUS,C
GOTO D2_GT_D2
D1_GT_D1
MOVF data2,W
GOTO PROC_END
D2_GT_D2
MOVF data1,W
PROC_END
MOVWF result |
|
|
|
| ▼零かどうかによる分岐 |
減算等の結果を利用して分岐する.
演算結果は STASTUS レジスタのZ ビットで判断する.
例として,変数 data1 と data2 が等しければ data1 を,等しくなければ data2 を変数 result に格納するコードを考える. |
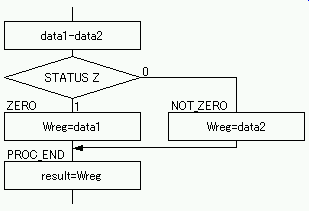 data1-data2 を実行したとき: data1-data2 を実行したとき:
・data1=data2(差:0)なら Z=1.
・data1≠data2(差:0以外) ならZ=0.
Z による分岐は BTFSC 命令もしくはBTFSS 命令で行う.
また,単に等しいかどうかを調べるのであれば,算術加減算命令以外に XORWF/XORLW 命令も全く同様に利用できる.
|
・BTFSS を利用した場合
MOVF data2,W
SUBWF data1,W
BTFSS STATUS,Z
GOTO NOT_ZERO
ZERO
MOVF data1,W
GOTO PROC_END
NOT_ZERO
MOVF data2,W
PROC_END
MOVWF result |
・XORWF を利用した場合
MOVF data2,W
XORWF data1,W
BTFSS STATUS,Z
GOTO NOT_ZERO
ZERO
MOVF data1,W
GOTO PROC_END
NOT_ZERO
MOVF data2,W
PROC_END
MOVWF result |
|
|
|
| ▼カウントダウン結果による分岐 |
ループ処理ルーチンをプログラミングするには,変数から減算命令で1を減算して演算結果を
BTFSC 命令もしくはBTFSS 命令で検査しても良いが,カウンタ専用命令を利用する方法もある.
例として,変数 counter(初期値 20H)を 1 ずつ 0H になるまでカウントダウンし,最終値(0H)を変数 result に格納するコードを考える. |
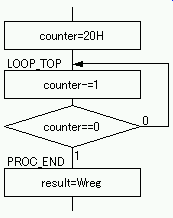 DECFSZ 命令は,任意のレジスタから1減算した結果が 0 であれば次の命令をスキップするため,ループカウンタの制御をシンプルにプログラミング可能である.
DECFSZ 命令は,任意のレジスタから1減算した結果が 0 であれば次の命令をスキップするため,ループカウンタの制御をシンプルにプログラミング可能である.
なお,同様な命令に INCFSZ 命令があるが,こちらはレジスタに 1 を加算した結果が 0(FFH→0Hになった場合)に同様な動作をする.
|
・DECFSZ を利用した場合
MOVLW 020H
MOVWF counter
LOOP_TOP
DECFSZ counter,F
GOTO LOOP_TOP
PROC_END
MOVWF result |
|
|
|
| ▼レジスタの任意ビットの状態による分岐 |
BTFSC 命令もしくはBTFSS 命令による分岐処理はSTATUS レジスタ以外のレジスタにも適用できる.
例として,PORTB レジスタの第 0 ビット(RB0)が 1 であれば変数 data1 を,0 であれば変数 data2 を変数 result
に格納するコードを考える. |
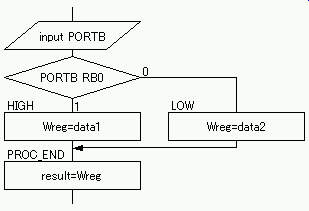 フローチャートでは,PORTB のデータ入力と第 0 ビットの判断が各々の記号により動作を記述されているが,BTFSS/BTFSC
命令は両動作を単独の命令で実行する. フローチャートでは,PORTB のデータ入力と第 0 ビットの判断が各々の記号により動作を記述されているが,BTFSS/BTFSC
命令は両動作を単独の命令で実行する.
なお,PORTB の第 0 ビットは事前に入力ポートの設定がなされていなければならない.
|
・BTFSS を利用した場合
BTFSS PORTB,0
GOTO PB0_LOW
PB0_HIGH
MOVF data1,W
GOTO PROC_END
PB0_LOW
MOVF data2,W
PROC_END
MOVWF result |
|
|
|
|
|
|
|
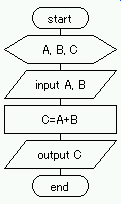 例題は,【データ A および B の入力(記憶)】→【A および B により C を計算】→【計算結果
C の出力】,という順番で処理でき,各処理は,それぞれ以下の記号で表示できる.
例題は,【データ A および B の入力(記憶)】→【A および B により C を計算】→【計算結果
C の出力】,という順番で処理でき,各処理は,それぞれ以下の記号で表示できる.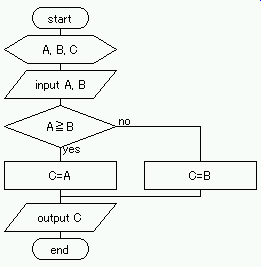 例題は,【A および B の入力(記憶)】→【A および B の大小判断】→【判断結果により C の値を決定】→【C の出力】,という順番で処理でき,各処理はそれぞれ以下の記号で表示できる.
例題は,【A および B の入力(記憶)】→【A および B の大小判断】→【判断結果により C の値を決定】→【C の出力】,という順番で処理でき,各処理はそれぞれ以下の記号で表示できる.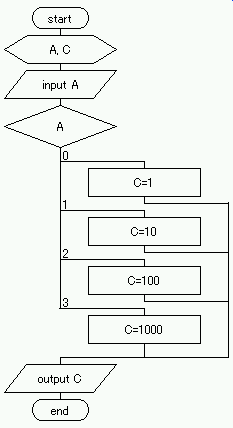 例題は,【A の入力(記憶)】→【A の値判断】→【判断結果により C の値を決定】→【C
の出力】,という順番で処理でき,各処理はそれぞれ以下の記号で表示できる.
例題は,【A の入力(記憶)】→【A の値判断】→【判断結果により C の値を決定】→【C
の出力】,という順番で処理でき,各処理はそれぞれ以下の記号で表示できる.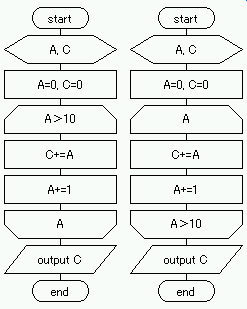 例題は,【A および C の初期値設定】→【A が 10 になるまで加算,A をインクリメント】→【C の出力】,という順番で処理でき,各処理はそれぞれ以下の記号で表示できる.
例題は,【A および C の初期値設定】→【A が 10 になるまで加算,A をインクリメント】→【C の出力】,という順番で処理でき,各処理はそれぞれ以下の記号で表示できる.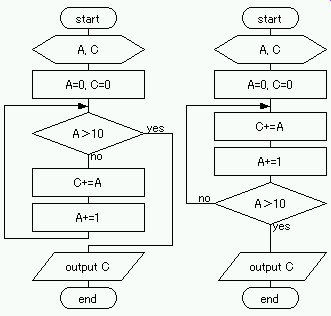 同じ例を判断記号を用いて表記すると図のようになる.
同じ例を判断記号を用いて表記すると図のようになる.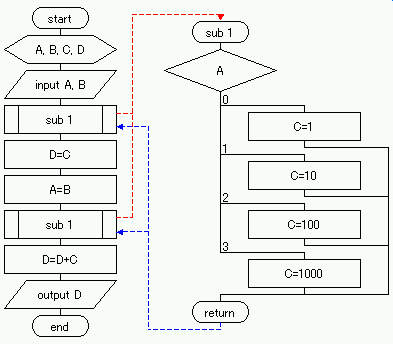 例題は,【A,B の入力(記憶)】および【D の出力】をメインルーチンで,【A および B の値判断】および【判断結果により C の値を決定】をサブルーチンで処理している・
例題は,【A,B の入力(記憶)】および【D の出力】をメインルーチンで,【A および B の値判断】および【判断結果により C の値を決定】をサブルーチンで処理している・